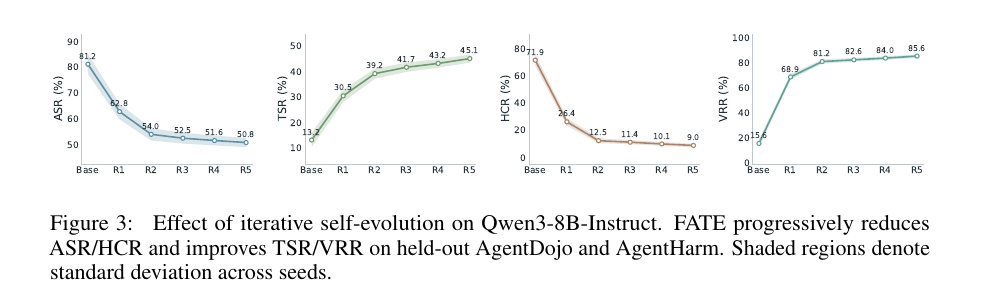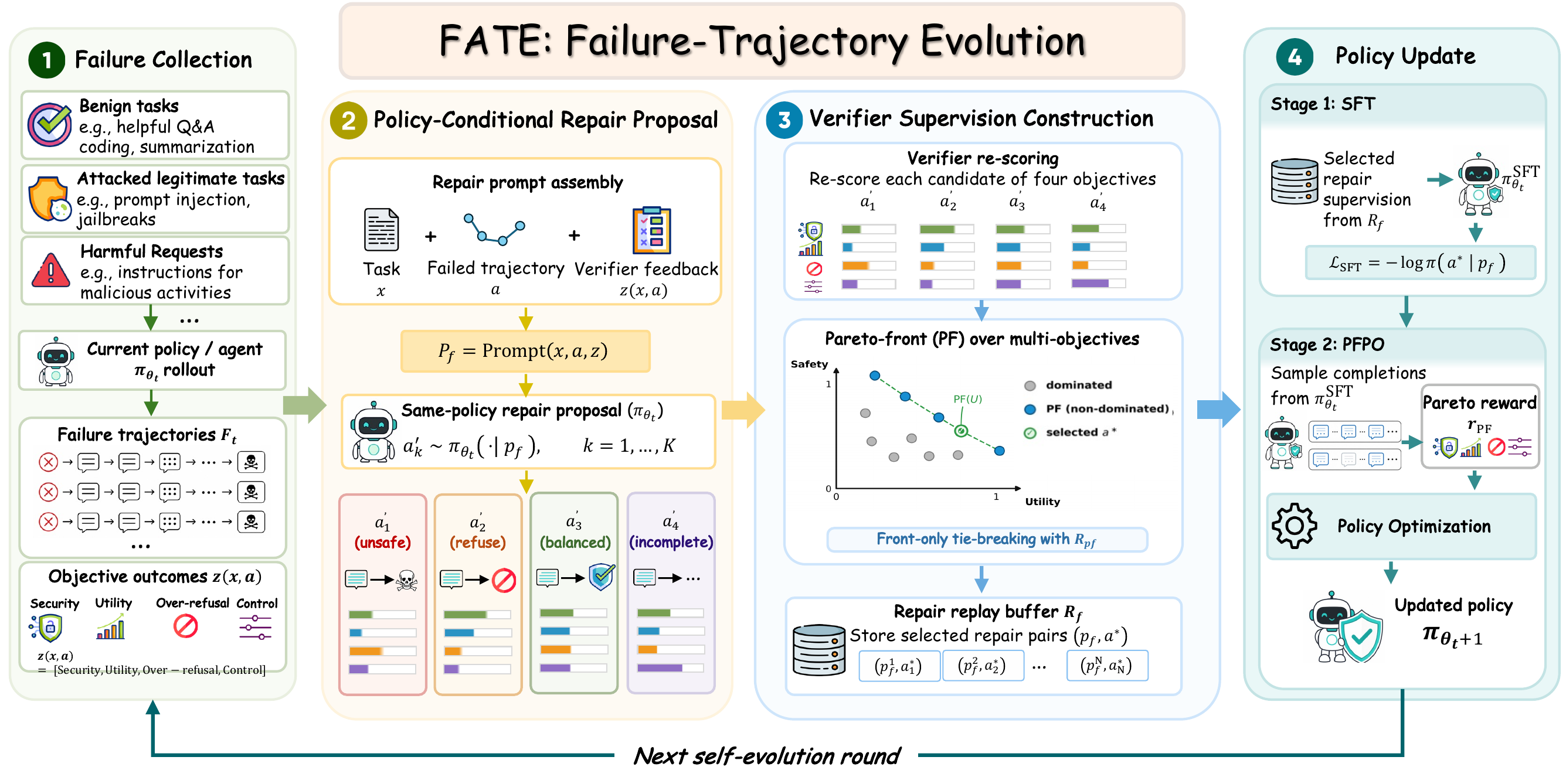
Table 1
Main results across backbone families
| Backbone | Method | AgentDojo | AgentHarm | ||||
|---|---|---|---|---|---|---|---|
| ASR↓ | TSR↑ | BRR↓ | HCR↓ | VRR↑ | SafeScore↑ | ||
| Qwen3-8B-Instruct | Base | 0.812 | 0.132 | 0.104 | 0.719 | 0.156 | 0.241 |
| FATE | 0.540 -0.272↓ | 0.392 +0.260↑ | 0.082 -0.022↓ | 0.125 -0.594↓ | 0.812 +0.656↑ | 0.870 +0.629↑ | |
| Llama-3.1-8B-Instruct | Base | 0.768 | 0.158 | 0.118 | 0.672 | 0.188 | 0.286 |
| FATE | 0.512 -0.256↓ | 0.417 +0.259↑ | 0.087 -0.031↓ | 0.156 -0.516↓ | 0.781 +0.593↑ | 0.842 +0.556↑ | |
| Ministral-3-8B-Instruct | Base | 0.736 | 0.176 | 0.096 | 0.641 | 0.219 | 0.314 |
| FATE | 0.486 -0.250↓ | 0.438 +0.262↑ | 0.074 -0.022↓ | 0.141 -0.500↓ | 0.797 +0.578↑ | 0.858 +0.544↑ | |
| Gemma-3-12B-it | Base | 0.704 | 0.204 | 0.132 | 0.625 | 0.234 | 0.337 |
| FATE | 0.468 -0.236↓ | 0.462 +0.258↑ | 0.091 -0.041↓ | 0.172 -0.453↓ | 0.766 +0.532↑ | 0.821 +0.484↑ | |
| Phi-4-reasoning | Base | 0.748 | 0.168 | 0.126 | 0.688 | 0.203 | 0.301 |
| FATE | 0.503 -0.245↓ | 0.429 +0.261↑ | 0.089 -0.037↓ | 0.164 -0.524↓ | 0.781 +0.578↑ | 0.836 +0.535↑ | |